第5节 设计并写出优雅的Go语言项目
❤️💕💕During the winter vacation, I followed up and learned two projects: tiktok project and IAM project, and summarized and practiced the CloudNative project and Go language. I learned a lot in the process.Myblog:http://nsddd.top
[TOC]
Go语言
Go 语言简单易学,对于大部分开发者来说,编写可运行的代码并不是一件难事,但如果想真正成为 Go 编程高手,你需要花很多精力去研究 Go 的编程哲学。
在我的 Go 开发生涯中,我见过各种各样的代码问题,例如:代码不规范,难以阅读;函数共享性差,代码重复率高;不是面向接口编程,代码扩展性差,代码不可测;代码质量低下。究其原因,是因为这些代码的开发者很少花时间去认真研究如何开发一个优雅的 Go 项目,更多时间是埋头在需求开发中。
如何开发出一个优雅的Go语言项目
先来看第一个问题。Go 项目是一个偏工程化的概念,不仅包含了 Go 应用,还包含了项目管理和项目文档:
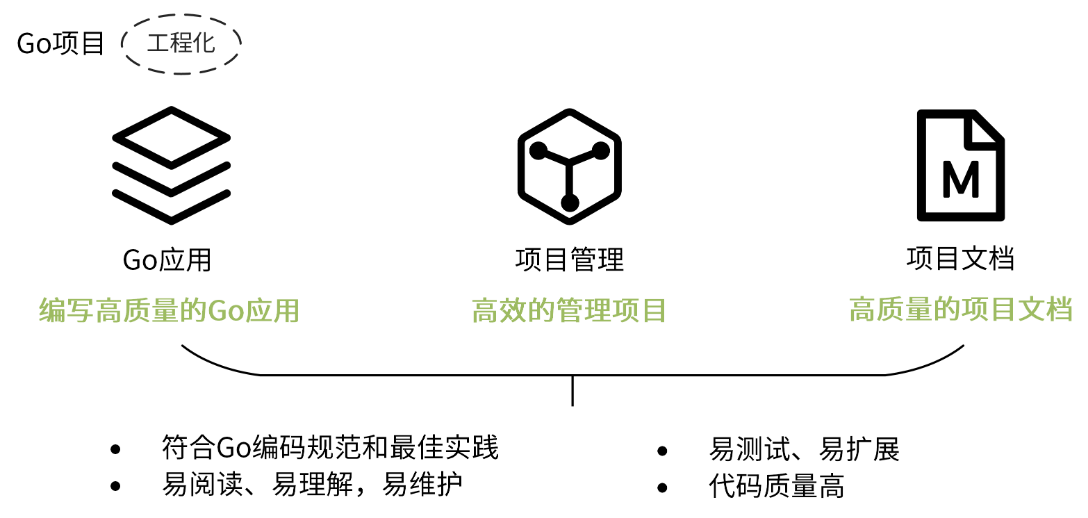
这就来到了第二个问题,一个优雅的 Go 项目,不仅要求我们的 Go 应用是优雅的,还要确保我们的项目管理和文档也是优雅的。这样,我们根据前面几讲学到的 Go 设计规范,很容易就能总结出一个优雅的 Go 应用需要具备的特点:
- 符合 Go 编码规范和最佳实践;
- 易阅读、易理解,易维护;
- 易测试、易扩展;
- 代码质量高。
解决了这两个问题,让我们回到这一讲的核心问题:如何写出优雅的 Go 项目?
写出一个优雅的 Go 项目,在我看来,就是用“最佳实践”的方式去实现 Go 项目中的 Go 应用、项目管理和项目文档。具体来说,就是编写高质量的 Go 应用、高效管理项目、编写高质量的项目文档。
编写高质量的Go语言项目
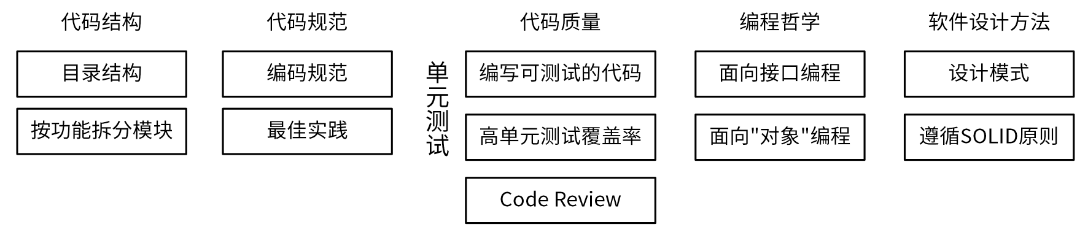
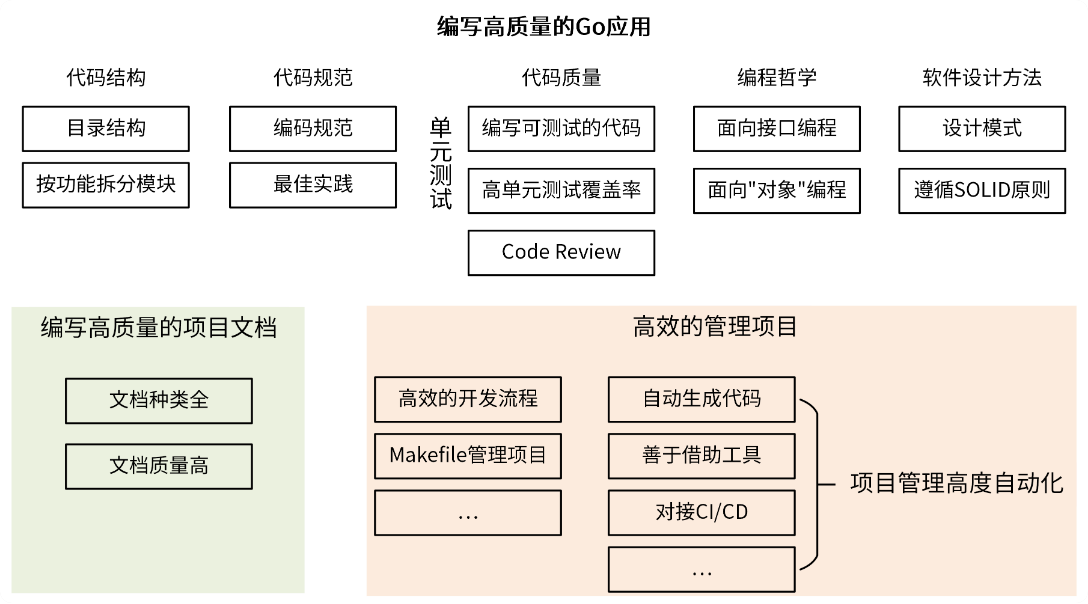
基于我的研发经验,要编写一个高质量的 Go 应用,其实可以归纳为 5 个方面:代码结构、代码规范、代码质量、编程哲学和软件设计方法,见下图。
项目结构
为什么先说代码结构呢?因为组织合理的代码结构是一个项目的门面。我们可以通过两个手段来组织代码结构。
第一个手段是,组织一个好的目录结构。
第二个手段是,选择一个好的模块拆分方法。做好模块拆分,可以使项目内模块职责分明,做到低耦合高内聚。
那么 Go 项目开发中,如何拆分模块呢?目前业界有两种拆分方法,分别是按层拆分和按功能拆分。
首先,我们看下按层拆分,最典型的是 MVC 架构中的模块拆分方式。在 MVC 架构中,我们将服务中的不同组件按访问顺序,拆分成了 Model、View 和 Controller 三层。
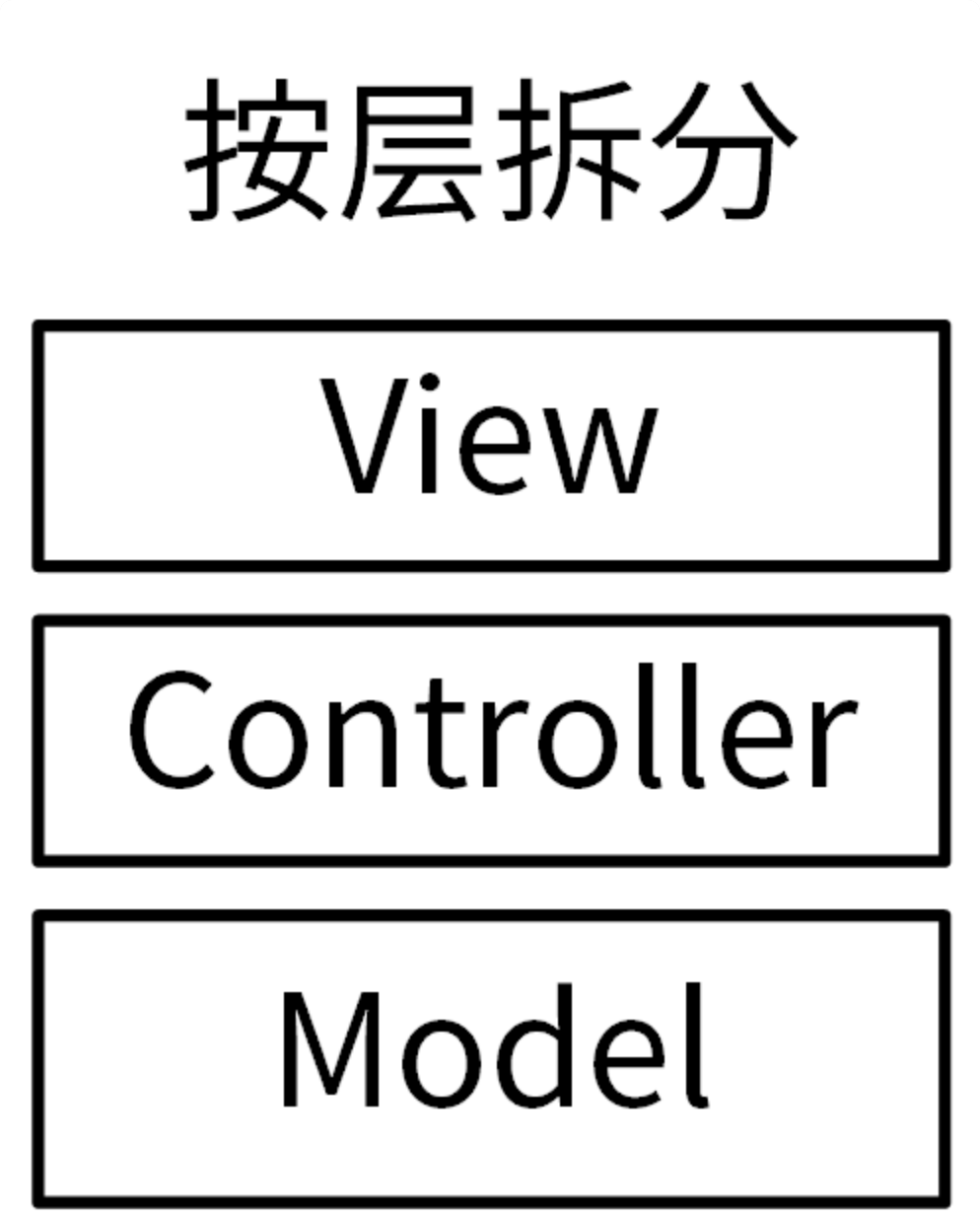
每层完成不同的功能:
- View(视图)是提供给用户的操作界面,用来处理数据的显示。
- Controller(控制器),负责根据用户从 View 层输入的指令,选取 Model 层中的数据,然后对其进行相应的操作,产生最终结果。
- Model(模型),是应用程序中用于处理数据逻辑的部分。
我们看一个典型的按层拆分的目录结构:
$ tree --noreport -L 2 layers
layers
├── controllers
│ ├── billing
│ ├── order
│ └── user
├── models
│ ├── billing.go
│ ├── order.go
│ └── user.go
└── views
└── layouts
在 Go 项目中,按层拆分会带来很多问题。最大的问题是循环引用:相同功能可能在不同层被使用到,而这些功能又分散在不同的层中,很容易造成循环引用。
所以,你只要大概知道按层拆分是什么意思就够了,在 Go 项目中我建议你使用的是按功能拆分的方法,这也是 Go 项目中最常见的拆分方法。
比如,一个订单系统,我们可以根据不同功能将其拆分成用户(user)、订单(order)和计费(billing)3 个模块,每一个模块提供独立的功能,功能更单一:
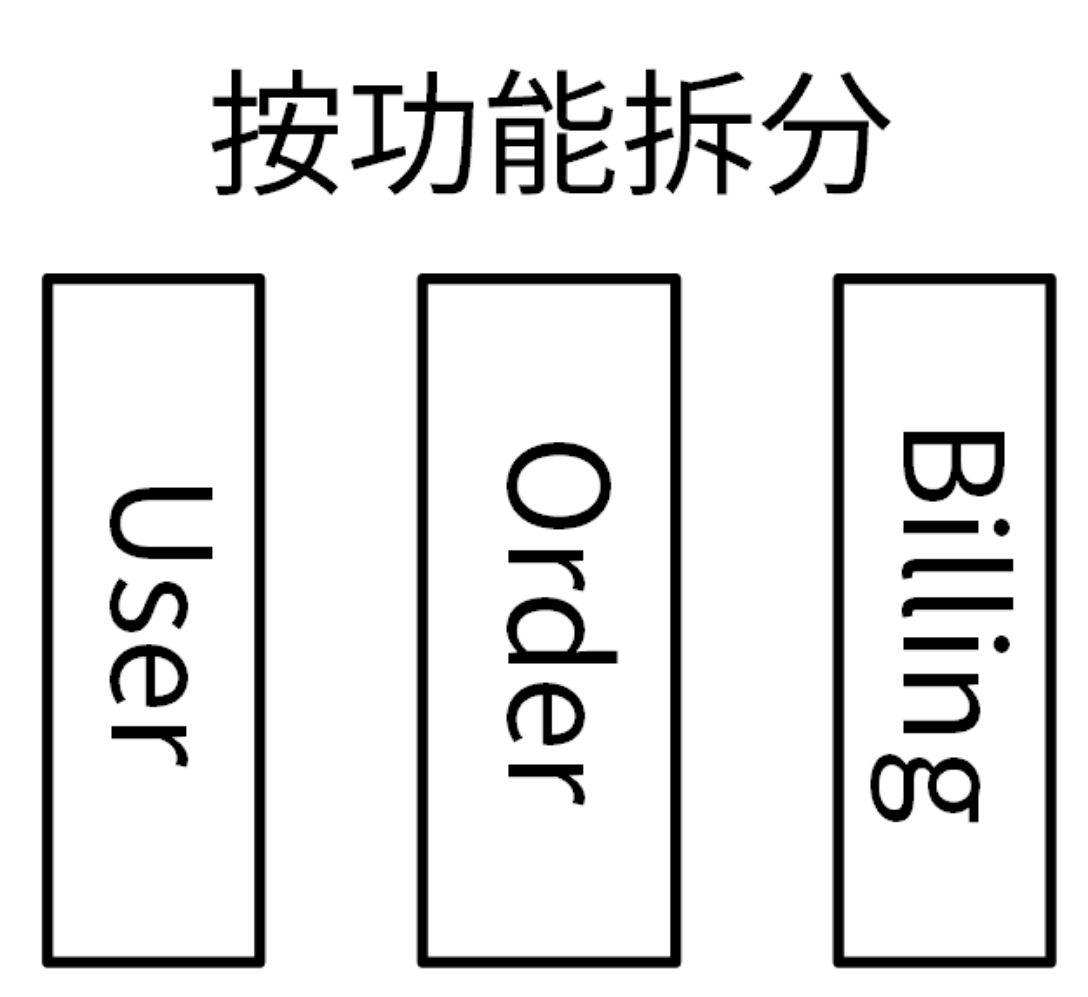
下面是该订单系统的代码目录结构:
$ tree pkg
$ tree --noreport -L 2 pkg
pkg
├── billing
├── order
│ └── order.go
└── user
相较于按层拆分,按功能拆分模块带来的好处也很好理解:
- 不同模块,功能单一,可以实现高内聚低耦合的设计哲学。
- 因为所有的功能只需要实现一次,引用逻辑清晰,会大大减少出现循环引用的概率。
所以,有很多优秀的 Go 项目采用的都是按功能拆分的模块拆分方式,例如 Kubernetes、Docker、Helm、Prometheus 等。
除了组织合理的代码结构这种方式外,编写高质量 Go 应用的另外一个行之有效的方法,是遵循 Go 语言代码规范来编写代码。在我看来,这也是最容易出效果的方式。
代码规范
首先,我们的代码要符合 Go 编码规范,这是最容易实现的途径。Go 社区有很多这类规范可供参考,其中,比较受欢迎的是Uber Go 语言编码规范。
使用静态代码检查工具来约束开发者的行为:
有了静态代码检查工具后,不仅可以确保开发者写出的每一行代码都是符合 Go 编码规范的,还可以将静态代码检查集成到 CI/CD 流程中。这样,在代码提交后自动地检查代码,就保证了只有符合编码规范的代码,才会被合入主干。
Go 语言的静态代码检查工具有很多,目前用的最多的是 golangci-lint。
Go语言最佳实践文章:
- Effective Go:高效 Go 编程,由 Golang 官方编写,里面包含了编写 Go 代码的一些建议,也可以理解为最佳实践。
- Go Code Review Comments:Golang 官方编写的 Go 最佳实践,作为 Effective Go 的补充。
- Style guideline for Go packages:包含了如何组织 Go 包、如何命名 Go 包、如何写 Go 包文档的一些建议。
代码质量
有了组织合理的代码结构、符合 Go 语言代码规范的 Go 应用代码之后,我们还需要通过一些手段来确保我们开发出的是一个高质量的代码,这可以通过单元测试和 Code Review 来实现。
单元测试非常重要。我们开发完一段代码后,第一个执行的测试就是单元测试。它可以保证我们的代码是符合预期的,一些异常变动能够被及时感知到。进行单元测试,不仅需要编写单元测试用例,还需要我们确保代码是可测试的,以及具有一个高的单元测试覆盖率。
可测试代码编写:
如果我们要对函数 A 进行测试,并且 A 中的所有代码均能够在单元测试环境下按预期被执行,那么函数 A 的代码块就是可测试的。我们来看下一般的单元测试环境有什么特点:
- 可能无法连接数据库。
- 可能无法访问第三方服务。
如果函数 A 依赖数据库连接、第三方服务,那么在单元测试环境下执行单元测试就会失败,函数就没法测试,函数是不可测的。
解决方法也很简单:将依赖的数据库、第三方服务等抽象成接口,在被测代码中调用接口的方法,在测试时传入 mock 类型,从而将数据库、第三方服务等依赖从具体的被测函数中解耦出去。如下图所示:
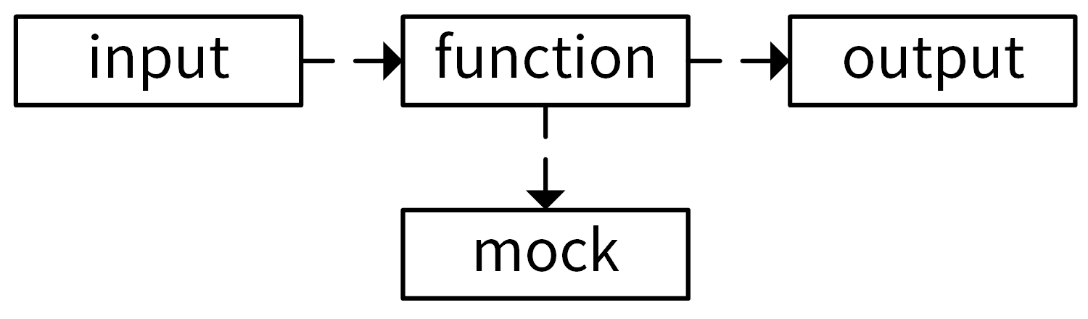
为了提高代码的可测性,降低单元测试的复杂度,对 function 和 mock 的要求是:
- 要尽可能减少 function 中的依赖,让 function 只依赖必要的模块。编写一个功能单一、职责分明的函数,会有利于减少依赖。
- 依赖模块应该是易 Mock 的。
为了协助你理解,我们先来看一段不可测试的代码:
package post
import "google.golang.org/grpc"
type Post struct {
Name string
Address string
}
func ListPosts(client *grpc.ClientConn) ([]*Post, error) {
return client.ListPosts()
}
这段代码中的 ListPosts 函数是不可测试的。因为 ListPosts 函数中调用了client.ListPosts()方法,该方法依赖于一个 gRPC 连接。而我们在做单元测试时,可能因为没有配置 gRPC 服务的地址、网络隔离等原因,导致没法建立 gRPC 连接,从而导致 ListPosts 函数执行失败。
我们将这段代码改成可依赖的:
package main
type Post struct {
Name string
Address string
}
type Service interface {
ListPosts() ([]*Post, error)
}
func ListPosts(svc Service) ([]*Post, error) {
return svc.ListPosts()
}
上面代码中,ListPosts 函数入参为 Service 接口类型,只要我们传入一个实现了 Service 接口类型的实例,ListPosts 函数即可成功运行。因此,我们可以在单元测试中可以实现一个不依赖任何第三方服务的 fake 实例,并传给 ListPosts。上述可测代码的单元测试代码如下:
package main
import "testing"
type fakeService struct {
}
func NewFakeService() Service {
return &fakeService{}
}
func (s *fakeService) ListPosts() ([]*Post, error) {
posts := make([]*Post, 0)
posts = append(posts, &Post{
Name: "colin",
Address: "Shenzhen",
})
posts = append(posts, &Post{
Name: "alex",
Address: "Beijing",
})
return posts, nil
}
func TestListPosts(t *testing.T) {
fake := NewFakeService()
if _, err := ListPosts(fake); err != nil {
t.Fatal("list posts failed")
}
}
当我们的代码可测之后,就可以借助一些工具来 Mock 需要的接口了。常用的 Mock 工具,有这么几个:
- golang/mock,是官方提供的 Mock 框架。它实现了基于 interface 的 Mock 功能,能够与 Golang 内置的 testing 包做很好的集成,是最常用的 Mock 工具。golang/mock 提供了 mockgen 工具用来生成 interface 对应的 Mock 源文件。
- sqlmock,可以用来模拟数据库连接。数据库是项目中比较常见的依赖,在遇到数据库依赖时都可以用它。
- httpmock,可以用来 Mock HTTP 请求。
- bouk/monkey,猴子补丁,能够通过替换函数指针的方式来修改任意函数的实现。如果 golang/mock、sqlmock 和 httpmock 这几种方法都不能满足我们的需求,我们可以尝试通过猴子补丁的方式来 Mock 依赖。可以这么说,猴子补丁提供了单元测试 Mock 依赖的最终解决方案。
接下来,我们再一起看看如何提高我们的单元测试覆盖率。
当我们编写了可测试的代码之后,接下来就需要编写足够的测试用例,用来提高项目的单元测试覆盖率。这里我有以下两个建议供你参考:
- 使用 gotests 工具自动生成单元测试代码,减少编写单元测试用例的工作量,将你从重复的劳动中解放出来。
- 定期检查单元测试覆盖率。你可以通过以下方法来检查:
$ go test -race -cover -coverprofile=./coverage.out -timeout=10m -short -v ./...
$ go tool cover -func ./coverage.out
🚀 编译结果如下:
在提高项目的单元测试覆盖率时,我们可以先提高单元测试覆盖率低的函数,之后再检查项目的单元测试覆盖率;如果项目的单元测试覆盖率仍然低于期望的值,可以再次提高单元测试覆盖率低的函数的覆盖率,然后再检查。以此循环,最终将项目的单元测试覆盖率优化到预期的值为止。
这里要注意,对于一些可能经常会变动的函数单元测试,覆盖率要达到 100%。
说完了单元测试,我们再看看如何通过 Code Review 来保证代码质量。
Code Review 可以提高代码质量、交叉排查缺陷,并且促进团队内知识共享,是保障代码质量非常有效的手段。在我们的项目开发中,一定要建立一套持久可行的 Code Review 机制。
但在我的研发生涯中,发现很多团队没有建立有效的 Code Review 机制。这些团队都认可 Code Review 机制带来的好处,但是因为流程难以遵守,慢慢地 Code Review 就变成了形式主义,最终不了了之。其实,建立 Code Review 机制很简单,主要有 3 点:
- 首先,确保我们使用的代码托管平台有 Code Review 的功能。比如,GitHub、GitLab 这类代码托管平台都具备这种能力。
- 接着,建立一套 Code Review 规范,规定如何进行 Code Review。
- 最后,也是最重要的,每次代码变更,相关开发人员都要去落实 Code Review 机制,并形成习惯,直到最后形成团队文化。
编程的内功
上面的都是外面的招式,真正影响到根骨的还得看内功:
那内功是什么呢?就是编程哲学和软件设计方法。
编程哲学
那编程哲学是什么意思呢?在我看来,编程哲学,其实就是要编写符合 Go 语言设计哲学的代码。Go 语言有很多设计哲学,对代码质量影响比较大的,我认为有两个:面向接口编程和面向“对象”编程。
面向接口编程
Go 接口是一组方法的集合。任何类型,只要实现了该接口中的方法集,那么就属于这个类型,也称为实现了该接口。
接口的作用,其实就是为不同层级的模块提供一个定义好的中间层。这样,上游不再需要依赖下游的具体实现,充分地对上下游进行了解耦。很多流行的 Go 设计模式,就是通过面向接口编程的思想来实现的。
我们看一个面向接口编程的例子。下面这段代码定义了一个Bird接口,Canary 和 Crow 类型均实现了Bird接口。
package main
import "fmt"
// 定义了一个鸟类
type Bird interface {
Fly()
Type() string
}
// 鸟类:金丝雀
type Canary struct {
Name string
}
func (c *Canary) Fly() {
fmt.Printf("我是%s,用黄色的翅膀飞\n", c.Name)
}
func (c *Canary) Type() string {
return c.Name
}
// 鸟类:乌鸦
type Crow struct {
Name string
}
func (c *Crow) Fly() {
fmt.Printf("我是%s,我用黑色的翅膀飞\n", c.Name)
}
func (c *Crow) Type() string {
return c.Name
}
// 让鸟类飞一下
func LetItFly(bird Bird) {
fmt.Printf("Let %s Fly!\n", bird.Type())
bird.Fly()
}
func main() {
LetItFly(&Canary{"金丝雀"})
LetItFly(&Crow{"乌鸦"})
}
package main
import "fmt"
// 定义了一个鸟类
type Bird interface {
Fly()
Type() string
}
// 鸟类:金丝雀
type Canary struct {
Name string
}
func (c *Canary) Fly() {
fmt.Printf("我是%s,用黄色的翅膀飞\n", c.Name)
}
func (c *Canary) Type() string {
return c.Name
}
// 鸟类:乌鸦
type Crow struct {
Name string
}
func (c *Crow) Fly() {
fmt.Printf("我是%s,我用黑色的翅膀飞\n", c.Name)
}
func (c *Crow) Type() string {
return c.Name
}
// 让鸟类飞一下
func LetItFly(bird Bird) {
fmt.Printf("Let %s Fly!\n", bird.Type())
bird.Fly()
}
func main() {
LetItFly(&Canary{"金丝雀"})
LetItFly(&Crow{"乌鸦"})
}
这段代码中,因为 Crow 和 Canary 都实现了 Bird 接口声明的 Fly、Type 方法,所以可以说 Crow、Canary 实现了 Bird 接口,属于 Bird 类型。在函数调用时,可以传入 Bird 类型,并在函数内部调用 Bird 接口提供的方法,以此来解耦 Bird 的具体实现。
好了,我们总结下使用接口的好处吧:
- 代码扩展性更强了。例如,同样的 Bird,可以有不同的实现。在开发中用的更多的是,将数据库的 CURD 操作抽象成接口,从而可以实现同一份代码对接不同数据库的目的。
- 可以解耦上下游的实现。例如,LetItFly 不用关注 Bird 是如何 Fly 的,只需要调用 Bird 提供的方法即可。
- 提高了代码的可测性。因为接口可以解耦上下游实现,我们在单元测试需要依赖第三方系统 / 数据库的代码时,可以利用接口将具体实现解耦,实现 fake 类型。
- 代码更健壮、更稳定了。例如,如果要更改 Fly 的方式,只需要更改相关类型的 Fly 方法即可,完全影响不到 LetItFly 函数。
所以,我建议你,在 Go 项目开发中,一定要多思考,那些可能有多种实现的地方,要考虑使用接口。
接下来,我们再来看下面向“对象”编程。
面向对象编程(OOP)有很多优点,例如可以使我们的代码变得易维护、易扩展,并能提高开发效率等,所以一个高质量的 Go 应用在需要时,也应该采用面向对象的方法去编程。那什么叫“在需要时”呢?就是我们在开发代码时,如果一个功能可以通过接近于日常生活和自然的思考方式来实现,这时候就应该考虑使用面向对象的编程方法。
Go 语言不支持面向对象编程,但是却可以通过一些语言级的特性来实现类似的效果。
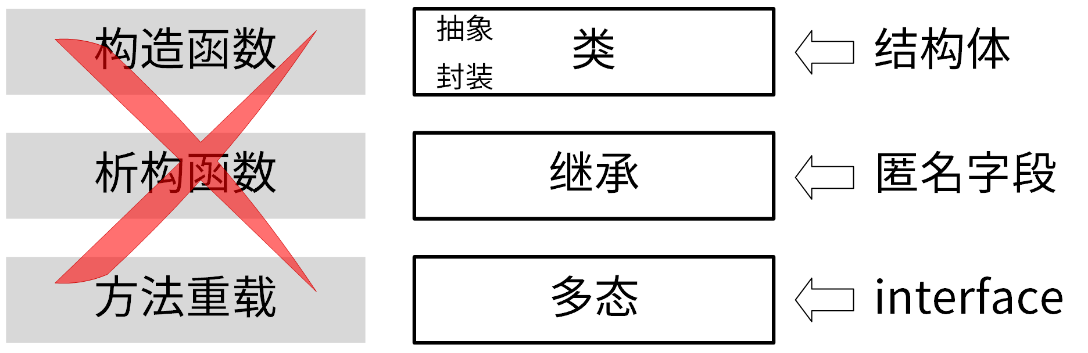
面向对象编程中,有几个核心特性:类、实例、抽象,封装、继承、多态、构造函数、析构函数、方法重载、this 指针。在 Go 中可以通过以下几个方式来实现类似的效果:
- 类、抽象、封装通过结构体来实现。
- 实例通过结构体变量来实现。
- 多态通过接口来实现。
- 继承通过组合来实现。
这里解释下什么叫组合:一个结构体嵌到另一个结构体,称作组合。例如一个结构体包含了一个匿名结构体,就说这个结构体组合了该匿名结构体。
软件设计方法
接下来,我们继续学习编写高质量 Go 代码的第二项内功,也就是让编写的代码遵循一些业界沉淀下来的,优秀的软件设计方法。
优秀的软件设计方法有很多,其中有两类方法对我们代码质量的提升特别有帮助,分别是设计模式(Design pattern)和 SOLID 原则。
在我看来,设计模式可以理解为业界针对一些特定的场景总结出来的最佳实现方式。它的特点是解决的场景比较具体,实施起来会比较简单;而 SOLID 原则更侧重设计原则,需要我们彻底理解,并在编写代码时多思考和落地。
我们先了解下有哪些设计模式。
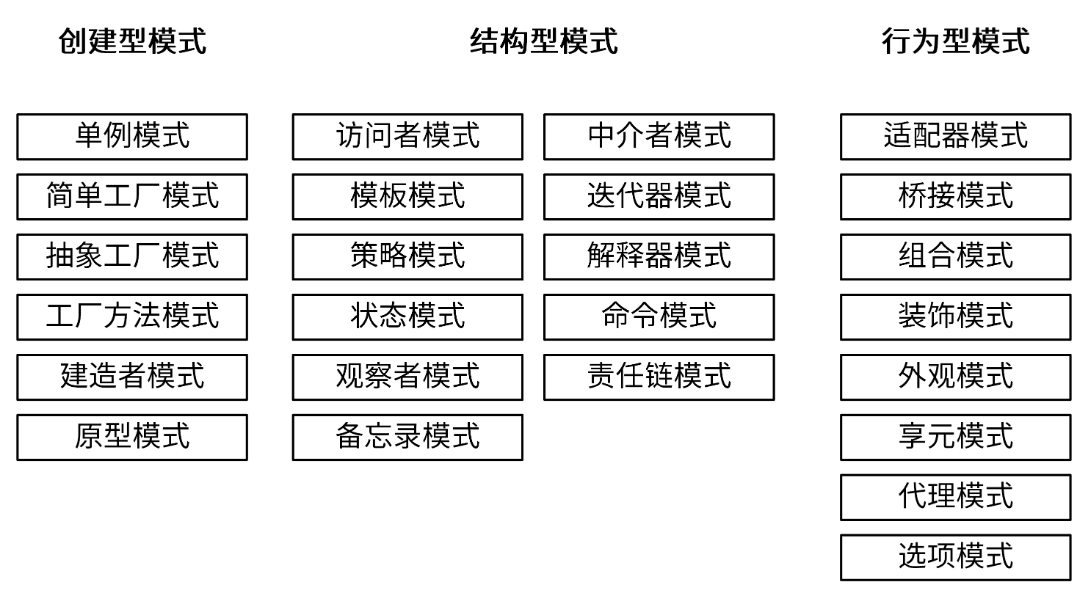
在软件领域,沉淀了一些比较优秀的设计模式,其中最受欢迎的是 GOF 设计模式。GOF 设计模式中包含了 3 大类(创建型模式、结构型模式、行为型模式),共 25 种经典的、可以解决常见软件设计问题的设计方案。这 25 种设计方案同样也适用于 Go 语言开发的项目。
如果说设计模式解决的是具体的场景,那么 SOLID 原则就是我们设计应用代码时的指导方针。
SOLID 原则,是由罗伯特·C·马丁在 21 世纪早期引入的,包括了面向对象编程和面向对象设计的五个基本原则:
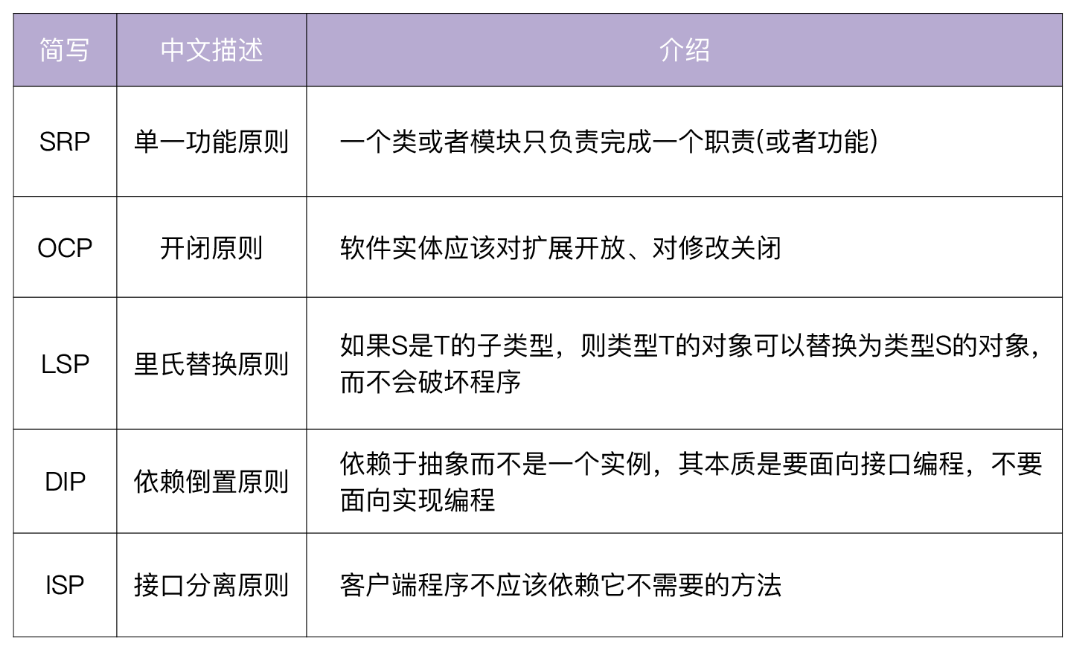
遵循 SOLID 原则可以确保我们设计的代码是易维护、易扩展、易阅读的。SOLID 原则同样也适用于 Go 程序设计。
如果你需要更详细地了解 SOLID 原则,可以参考下SOLID 原则介绍这篇文章。
到这里,我们就学完了“编写高质量的 Go 应用”这部分内容。接下来,我们再来学习下如何高效管理 Go 项目,以及如何编写高质量的项目文档。这里面的大部分内容,之前我们都有学习过,因为它们是“如何写出优雅的 Go 项目”的重要组成部分,所以,这里我仍然会简单介绍下它们。
高效管理项目
不同团队、不同项目会采用不同的方法来管理项目,在我看来比较重要的有 3 点,分别是制定一个高效的开发流程、使用 Makefile 管理项目和将项目管理自动化。我们可以通过自动生成代码、借助工具、对接 CI/CD 系统等方法来将项目管理自动化。具体见下图:
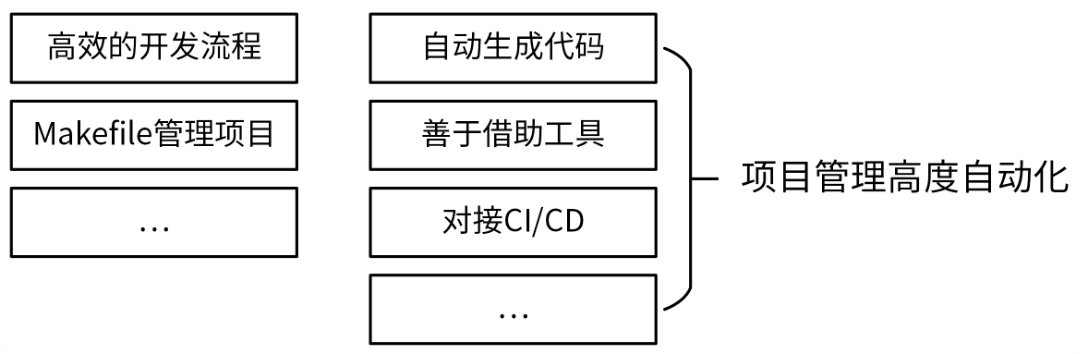
高效的开发流程
高效管理项目的第一步,就是要有一个高效的开发流程,这可以提高开发效率、减少软件维护成本。你可以回想一下设计开发流程的知识,如果印象比较模糊了,一定要回去复习下 08 讲的内容,因为这部分很重要 。
使用 Makefile 管理项目
为了更好地管理项目,除了一个高效的开发流程之外,使用 Makefile 也很重要。Makefile 可以将项目管理的工作通过 Makefile 依赖的方式实现自动化,除了可以提高管理效率之外,还能够减少人为操作带来的失误,并统一操作方式,使项目更加规范。
IAM 项目的所有操作均是通过 Makefile 来完成的,具体 Makefile 完成了如下操作:
build Build source code for host platform.
build.multiarch Build source code for multiple platforms. See option PLATFORMS.
image Build docker images for host arch.
image.multiarch Build docker images for multiple platforms. See option PLATFORMS.
push Build docker images for host arch and push images to registry.
push.multiarch Build docker images for multiple platforms and push images to registry.
deploy Deploy updated components to development env.
clean Remove all files that are created by building.
lint Check syntax and styling of go sources.
test Run unit test.
cover Run unit test and get test coverage.
release Release iam
format Gofmt (reformat) package sources (exclude vendor dir if existed).
verify-copyright Verify the boilerplate headers for all files.
add-copyright Ensures source code files have copyright license headers.
gen Generate all necessary files, such as error code files.
ca Generate CA files for all iam components.
install Install iam system with all its components.
swagger Generate swagger document.
serve-swagger Serve swagger spec and docs.
dependencies Install necessary dependencies.
tools install dependent tools.
check-updates Check outdated dependencies of the go projects.
help Show this help info.
自动生成代码(低代码)
低代码的理念现在越来越流行。虽然低代码有很多缺点,但确实有很多优点,例如:
- 自动化生成代码,减少工作量,提高工作效率。
- 代码有既定的生成规则,相比人工编写代码,准确性更高、更规范。
目前来看,自动生成代码现在已经成为趋势,比如 Kubernetes 项目有很多代码都是自动生成的。我认为,想写出一个优雅的 Go 项目,你也应该认真思考哪些地方的代码可以自动生成。在这门课的 IAM 项目中,就有大量的代码是自动生成的,我放在这里供你参考:
- 错误码、错误码说明文档。
- 自动生成缺失的 doc.go 文件。
- 利用 gotests 工具,自动生成单元测试用例。
- 使用 Swagger 工具,自动生成 Swagger 文档。
- 使用 Mock 工具,自动生成接口的 Mock 实例。
善于借助工具
在开发 Go 项目的过程中,我们也要善于借助工具,来帮助我们完成一部分工作。利用工具可以带来很多好处:
- 解放双手,提高工作效率。
- 利用工具的确定性,可以确保执行结果的一致性。例如,使用 golangci-lint 对代码进行检查,可以确保不同开发者开发的代码至少都遵循 golangci-lint 的代码检查规范。
- 有利于实现自动化,可以将工具集成到 CI/CD 流程中,触发流水线自动执行。
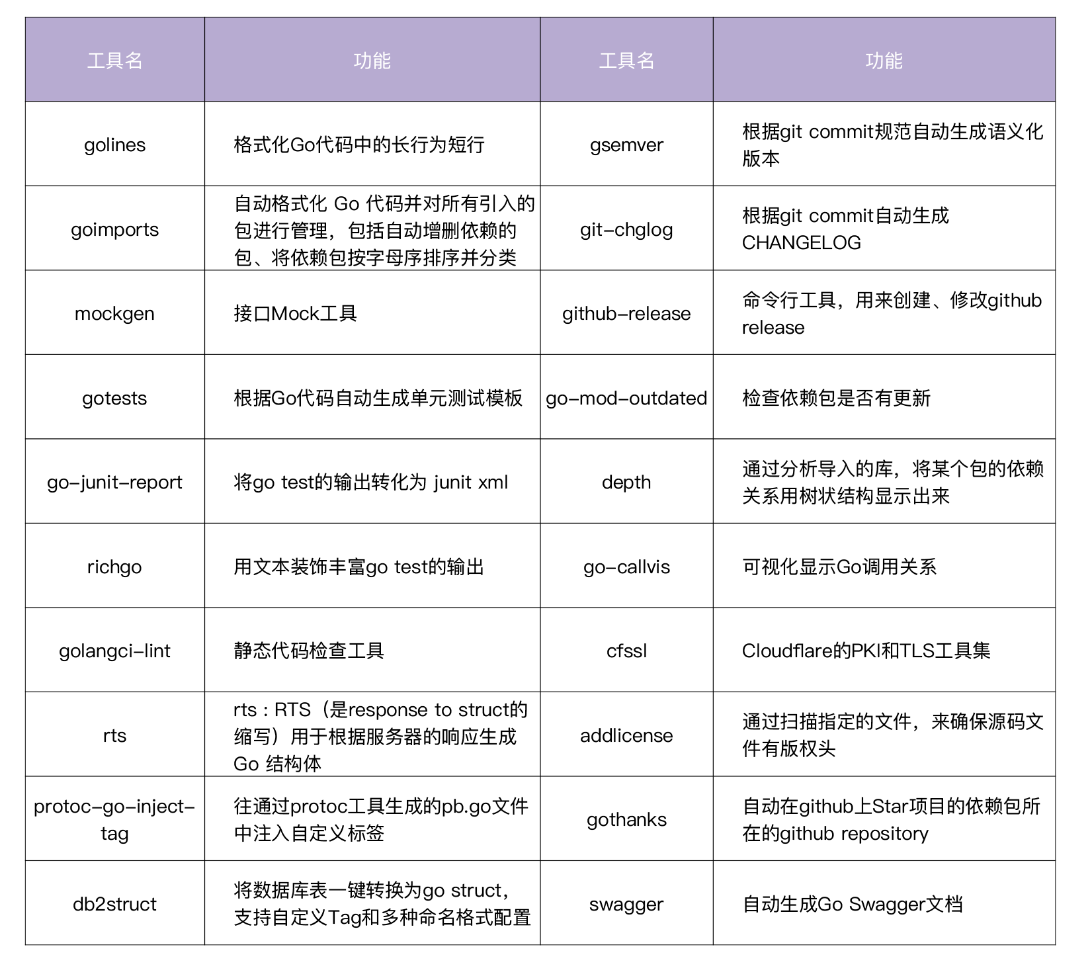
所有这些工具都可以通过下面的方式安装。
$ cd $IAM_ROOT
$ make tools.install
IAM 项目使用了上面这些工具的绝大部分,用来尽可能提高整个项目的自动化程度,提高项目维护效率。
对接CICD
代码在合并入主干时,应该有一套 CI/CD 流程来自动化地对代码进行检查、编译、单元测试等,只有通过后的代码才可以并入主干。通过 CI/CD 流程来保证代码的质量。当前比较流行的 CI/CD 工具有 Jenkins、GitLab、Argo、Github Actions、JenkinsX 等。
编写高质量的项目文档
最后,一个优雅的项目,还应该有完善的文档。例如 README.md、安装文档、开发文档、使用文档、API 接口文档、设计文档等等。
总结
设计模式
在软件开发中,经常会遇到各种各样的编码场景,这些场景往往重复发生,因此具有典型性。针对这些典型场景,我们可以自己编码解决,也可以采取更为省时省力的方式:直接采用设计模式。
设计模式是啥呢?简单来说,就是将软件开发中需要重复性解决的编码场景,按最佳实践的方式抽象成一个模型,模型描述的解决方法就是设计模式。使用设计模式,可以使代码更易于理解,保证代码的重用性和可靠性。
在软件领域,GoF(四人帮,全拼 Gang of Four)首次系统化提出了 3 大类、共 25 种可复用的经典设计方案,来解决常见的软件设计问题,为可复用软件设计奠定了一定的理论基础。
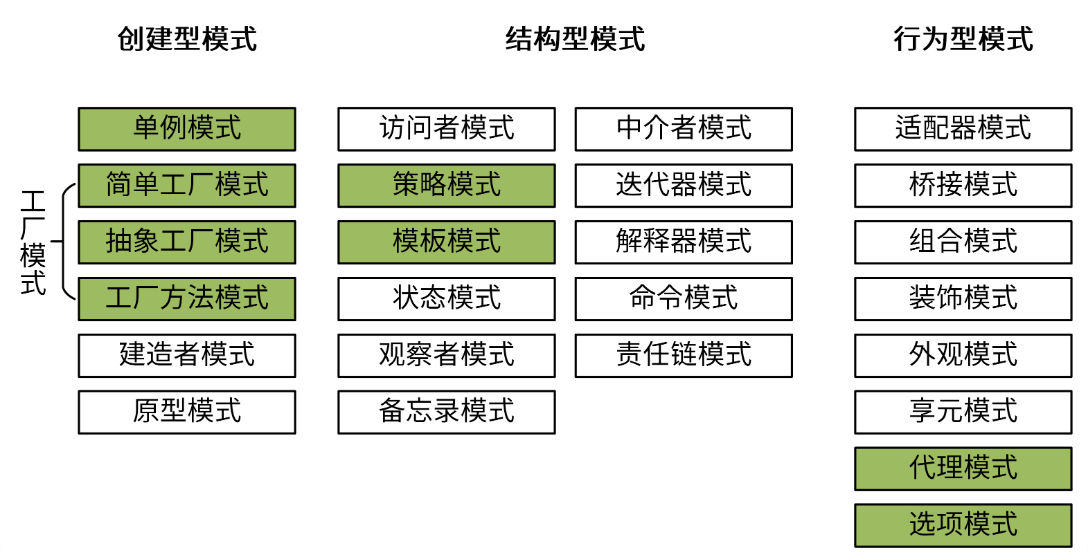
创建型模式
首先来看创建型模式(Creational Patterns),它提供了一种在创建对象的同时隐藏创建逻辑的方式,而不是使用 new 运算符直接实例化对象。
这种类型的设计模式里,单例模式和工厂模式(具体包括简单工厂模式、抽象工厂模式和工厂方法模式三种)在 Go 项目开发中比较常用。我们先来看单例模式。
单例模式
单例模式(Singleton Pattern),是最简单的一个模式。在 Go 中,单例模式指的是全局只有一个实例,并且它负责创建自己的对象。单例模式不仅有利于减少内存开支,还有减少系统性能开销、防止多个实例产生冲突等优点。
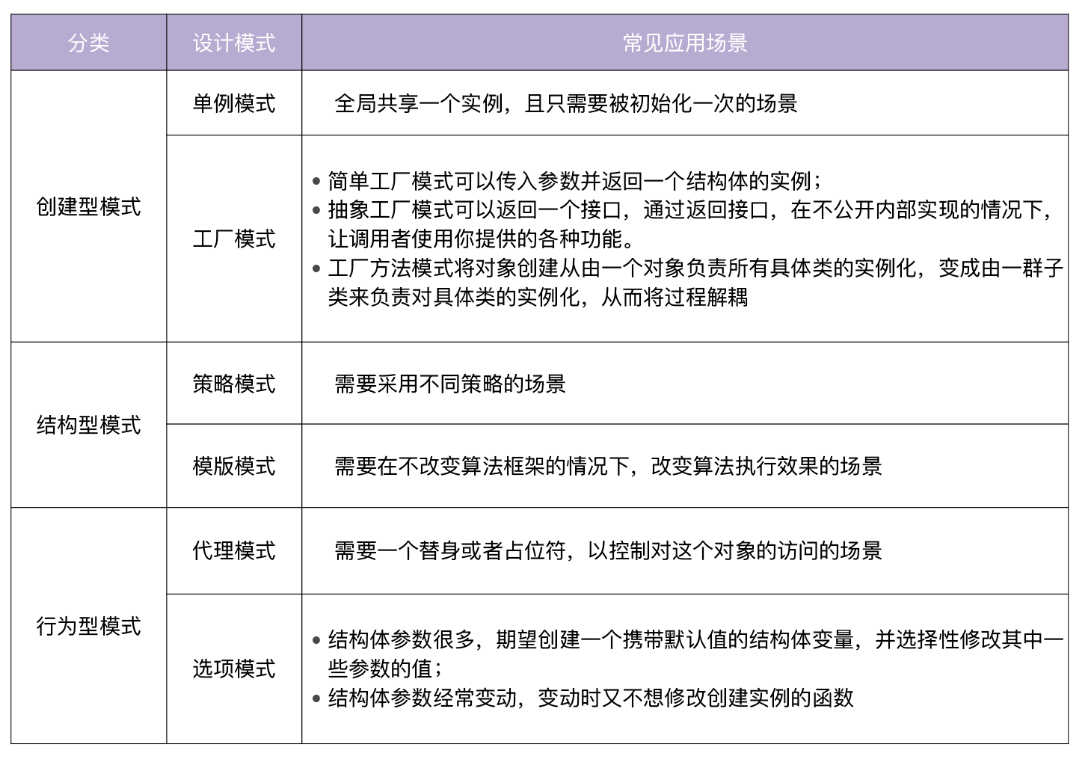
因为单例模式保证了实例的全局唯一性,而且只被初始化一次,所以比较适合全局共享一个实例,且只需要被初始化一次的场景,例如数据库实例、全局配置、全局任务池等。
单例模式又分为 饿汉方式 和 懒汉方式 。饿汉方式指全局的单例实例在包被加载时创建,而懒汉方式指全局的单例实例在第一次被使用时创建。你可以看到,这种命名方式非常形象地体现了它们不同的特点。
饿汉方式:
package singleton
type singleton struct {
}
var ins *singleton = &singleton{}
func GetInsOr() *singleton {
return ins
}
你需要注意,因为实例是在包被导入时初始化的,所以如果初始化耗时,会导致程序加载时间比较长。
懒汉方式是开源项目中使用最多的,但它的缺点是非并发安全,在实际使用时需要加锁。以下是懒汉方式不加锁的一个实现:
package singleton
type singleton struct {
}
var ins *singleton
func GetInsOr() *singleton {
if ins == nil {
ins = &singleton{}
}
return ins
}
可以看到,在创建 ins 时,如果 ins==nil,就会再创建一个 ins 实例,这时候单例就会有多个实例。
为了解决懒汉方式非并发安全的问题,需要对实例进行加锁,下面是带检查锁的一个实现:
import "sync"
type singleton struct {
}
var ins *singleton
var mu sync.Mutex
func GetIns() *singleton {
if ins == nil {
mu.Lock()
if ins == nil {
ins = &singleton{}
}
mu.Unlock()
}
return ins
}
上述代码只有在创建时才会加锁,既提高了代码效率,又保证了并发安全。
除了饿汉方式和懒汉方式,在 Go 开发中,还有一种更优雅的实现方式,我建议你采用这种方式,代码如下:
package singleton
import (
"sync"
)
type singleton struct {
}
var ins *singleton
var once sync.Once
func GetInsOr() *singleton {
once.Do(func() {
ins = &singleton{}
})
return ins
}
使用once.Do可以确保 ins 实例全局只被创建一次,once.Do 函数还可以确保当同时有多个创建动作时,只有一个创建动作在被执行。
另外,IAM 应用中大量使用了单例模式,如果你想了解更多单例模式的使用方式,可以直接查看 IAM 项目代码。IAM 中单例模式有GetStoreInsOr、GetEtcdFactoryOr、GetMySQLFactoryOr、GetCacheInsOr等。
工厂模式
工厂模式(Factory Pattern)是面向对象编程中的常用模式。在 Go 项目开发中,你可以通过使用多种不同的工厂模式,来使代码更简洁明了。Go 中的结构体,可以理解为面向对象编程中的类,例如 Person 结构体(类)实现了 Greet 方法。
type Person struct {
Name string
Age int
}
func (p Person) Greet() {
fmt.Printf("Hi! My name is %s", p.Name)
}
有了 Person“类”,就可以创建 Person 实例。我们可以通过简单工厂模式、抽象工厂模式、工厂方法模式这三种方式,来创建一个 Person 实例。
这三种工厂模式中,简单工厂模式是最常用、最简单的。它就是一个接受一些参数,然后返回 Person 实例的函数:
type Person struct {
Name string
Age int
}
func (p Person) Greet() {
fmt.Printf("Hi! My name is %s", p.Name)
}
func NewPerson(name string, age int) *Person {
return &Person{
Name: name,
Age: age,
}
}
和p:=&Person {}这种创建实例的方式相比,简单工厂模式可以确保我们创建的实例具有需要的参数,进而保证实例的方法可以按预期执行。例如,通过NewPerson创建 Person 实例时,可以确保实例的 name 和 age 属性被设置。
再来看抽象工厂模式,它和简单工厂模式的唯一区别,就是它返回的是接口而不是结构体。
通过返回接口,可以在你不公开内部实现的情况下,让调用者使用你提供的各种功能,例如:
type Person interface {
Greet()
}
type person struct {
name string
age int
}
func (p person) Greet() {
fmt.Printf("Hi! My name is %s", p.name)
}
// Here, NewPerson returns an interface, and not the person struct itself
func NewPerson(name string, age int) Person {
return person{
name: name,
age: age,
}
}
上面这个代码,定义了一个不可导出的结构体person,在通过 NewPerson 创建实例的时候返回的是接口,而不是结构体。
通过返回接口,我们还可以实现多个工厂函数,来返回不同的接口实现,例如:
// We define a Doer interface, that has the method signature
// of the `http.Client` structs `Do` method
type Doer interface {
Do(req *http.Request) (*http.Response, error)
}
// This gives us a regular HTTP client from the `net/http` package
func NewHTTPClient() Doer {
return &http.Client{}
}
type mockHTTPClient struct{}
func (*mockHTTPClient) Do(req *http.Request) (*http.Response, error) {
// The `NewRecorder` method of the httptest package gives us
// a new mock request generator
res := httptest.NewRecorder()
// calling the `Result` method gives us
// the default empty *http.Response object
return res.Result(), nil
}
// This gives us a mock HTTP client, which returns
// an empty response for any request sent to it
func NewMockHTTPClient() Doer {
return &mockHTTPClient{}
}
NewHTTPClient和NewMockHTTPClient都返回了同一个接口类型 Doer,这使得二者可以互换使用。当你想测试一段调用了 Doer 接口 Do 方法的代码时,这一点特别有用。因为你可以使用一个 Mock 的 HTTP 客户端,从而避免了调用真实外部接口可能带来的失败。
func QueryUser(doer Doer) error {
req, err := http.NewRequest("Get", "http://iam.api.marmotedu.com:8080/v1/secrets", nil)
if err != nil {
return err
}
_, err := doer.Do(req)
if err != nil {
return err
}
return nil
}
其测试用例为:
func TestQueryUser(t *testing.T) {
doer := NewMockHTTPClient()
if err := QueryUser(doer); err != nil {
t.Errorf("QueryUser failed, err: %v", err)
}
}
另外,在使用简单工厂模式和抽象工厂模式返回实例对象时,都可以返回指针。例如,简单工厂模式可以这样返回实例对象:
return &Person{
Name: name,
Age: age
}
抽象工厂模式可以这样返回实例对象:
return &person{
name: name,
age: age
}
在实际开发中,我建议返回非指针的实例,因为我们主要是想通过创建实例,调用其提供的方法,而不是对实例做更改。如果需要对实例做更改,可以实现SetXXX的方法。通过返回非指针的实例,可以确保实例的属性,避免属性被意外 / 任意修改。
在简单工厂模式中,依赖于唯一的工厂对象,如果我们需要实例化一个产品,就要向工厂中传入一个参数,获取对应的对象;如果要增加一种产品,就要在工厂中修改创建产品的函数。这会导致耦合性过高,这时我们就可以使用工厂方法模式。
在工厂方法模式中,依赖工厂函数,我们可以通过实现工厂函数来创建多种工厂,将对象创建从由一个对象负责所有具体类的实例化,变成由一群子类来负责对具体类的实例化,从而将过程解耦。
下面是工厂方法模式的一个代码实现:
type Person struct {
name string
age int
}
func NewPersonFactory(age int) func(name string) Person {
return func(name string) Person {
return Person{
name: name,
age: age,
}
}
}
然后,我们可以使用此功能来创建具有默认年龄的工厂:
newBaby := NewPersonFactory(1)
baby := newBaby("john")
newTeenager := NewPersonFactory(16)
teen := newTeenager("jill")
结构型模式
结构型模式(Structural Patterns),它的特点是关注类和对象的组合。这一类型里,我想详细讲讲策略模式和模板模式。
策略模式
策略模式(Strategy Pattern)定义一组算法,将每个算法都封装起来,并且使它们之间可以互换。
在项目开发中,我们经常要根据不同的场景,采取不同的措施,也就是不同的策略。比如,假设我们需要对 a、b 这两个整数进行计算,根据条件的不同,需要执行不同的计算方式。我们可以把所有的操作都封装在同一个函数中,然后通过 if ... else ... 的形式来调用不同的计算方式,这种方式称之为硬编码。
硬编码(hard-coding)是指在软件实现上,将输出或输入的相关参数(例如:路径、输出的形式或格式)直接以常量的方式撰写在源代码中,而非在执行期间由外界指定的设置、资源、资料或格式做出适当回应。一般被认定是种反模式或不完美的实现,因为软件受到输入资料
在实际应用中,随着功能和体验的不断增长,我们需要经常添加 / 修改策略,这样就需要不断修改已有代码,不仅会让这个函数越来越难维护,还可能因为修改带来一些 bug。所以为了解耦,需要使用策略模式,定义一些独立的类来封装不同的算法,每一个类封装一个具体的算法(即策略)。
下面是一个实现策略模式的代码:
package strategy
// 策略模式
// 定义一个策略类
type IStrategy interface {
do(int, int) int
}
// 策略实现:加
type add struct{}
func (*add) do(a, b int) int {
return a + b
}
// 策略实现:减
type reduce struct{}
func (*reduce) do(a, b int) int {
return a - b
}
// 具体策略的执行者
type Operator struct {
strategy IStrategy
}
// 设置策略
func (operator *Operator) setStrategy(strategy IStrategy) {
operator.strategy = strategy
}
// 调用策略中的方法
func (operator *Operator) calculate(a, b int) int {
return operator.strategy.do(a, b)
}
在上述代码中,我们定义了策略接口 IStrategy,还定义了 add 和 reduce 两种策略。最后定义了一个策略执行者,可以设置不同的策略,并执行,例如:
func TestStrategy(t *testing.T) {
operator := Operator{}
operator.setStrategy(&add{})
result := operator.calculate(1, 2)
fmt.Println("add:", result)
operator.setStrategy(&reduce{})
result = operator.calculate(2, 1)
fmt.Println("reduce:", result)
}
模板模式
模板模式 (Template Pattern) 定义一个操作中算法的骨架,而将一些步骤延迟到子类中。这种方法让子类在不改变一个算法结构的情况下,就能重新定义该算法的某些特定步骤。
简单来说,模板模式就是将一个类中能够公共使用的方法放置在抽象类中实现,将不能公共使用的方法作为抽象方法,强制子类去实现,这样就做到了将一个类作为一个模板,让开发者去填充需要填充的地方。
以下是模板模式的一个实现:
package template
import "fmt"
type Cooker interface {
fire()
cooke()
outfire()
}
// 类似于一个抽象类
type CookMenu struct {
}
func (CookMenu) fire() {
fmt.Println("开火")
}
// 做菜,交给具体的子类实现
func (CookMenu) cooke() {
}
func (CookMenu) outfire() {
fmt.Println("关火")
}
// 封装具体步骤
func doCook(cook Cooker) {
cook.fire()
cook.cooke()
cook.outfire()
}
//西红柿
type XiHongShi struct {
CookMenu
}
func (*XiHongShi) cooke() {
fmt.Println("做西红柿")
}
//鸡蛋
type ChaoJiDan struct {
CookMenu
}
func (ChaoJiDan) cooke() {
fmt.Println("做炒鸡蛋")
}
这里来看下测试用例:
func TestTemplate(t *testing.T) {
// 做西红柿
xihongshi := &XiHongShi{}
doCook(xihongshi)
fmt.Println("\n=====> 做另外一道菜")
// 做炒鸡蛋
chaojidan := &ChaoJiDan{}
doCook(chaojidan)
}
行为型模式
然后,让我们来看最后一个类别,行为型模式(Behavioral Patterns),它的特点是关注对象之间的通信。这一类别的设计模式中,我们会讲到代理模式和选项模式。
代理模式
代理模式 (Proxy Pattern),可以为另一个对象提供一个替身或者占位符,以控制对这个对象的访问。
以下代码是一个代理模式的实现:
package proxy
import "fmt"
type Seller interface {
sell(name string)
}
// 火车站
type Station struct {
stock int //库存
}
func (station *Station) sell(name string) {
if station.stock > 0 {
station.stock--
fmt.Printf("代理点中:%s买了一张票,剩余:%d \n", name, station.stock)
} else {
fmt.Println("票已售空")
}
}
// 火车代理点
type StationProxy struct {
station *Station // 持有一个火车站对象
}
func (proxy *StationProxy) sell(name string) {
if proxy.station.stock > 0 {
proxy.station.stock--
fmt.Printf("代理点中:%s买了一张票,剩余:%d \n", name, proxy.station.stock)
} else {
fmt.Println("票已售空")
}
}
上述代码中,StationProxy 代理了 Station,代理类中持有被代理类对象,并且和被代理类对象实现了同一接口。
选项模式
选项模式(Options Pattern)也是 Go 项目开发中经常使用到的模式,例如,grpc/grpc-go 的NewServer函数,uber-go/zap 包的New函数都用到了选项模式。使用选项模式,我们可以创建一个带有默认值的 struct 变量,并选择性地修改其中一些参数的值。
而在 Go 语言中,因为不支持给参数设置默认值,为了既能够创建带默认值的实例,又能够创建自定义参数的实例,不少开发者会通过以下两种方法来实现:
第一种方法,我们要分别开发两个用来创建实例的函数,一个可以创建带默认值的实例,一个可以定制化创建实例。
package options
import (
"time"
)
const (
defaultTimeout = 10
defaultCaching = false
)
type Connection struct {
addr string
cache bool
timeout time.Duration
}
// NewConnect creates a connection.
func NewConnect(addr string) (*Connection, error) {
return &Connection{
addr: addr,
cache: defaultCaching,
timeout: defaultTimeout,
}, nil
}
// NewConnectWithOptions creates a connection with options.
func NewConnectWithOptions(addr string, cache bool, timeout time.Duration) (*Connection, error) {
return &Connection{
addr: addr,
cache: cache,
timeout: timeout,
}, nil
}
使用这种方式,创建同一个 Connection 实例,却要实现两个不同的函数,实现方式很不优雅。
另外一种方法相对优雅些。我们需要创建一个带默认值的选项,并用该选项创建实例:
package options
import (
"time"
)
const (
defaultTimeout = 10
defaultCaching = false
)
type Connection struct {
addr string
cache bool
timeout time.Duration
}
type ConnectionOptions struct {
Caching bool
Timeout time.Duration
}
func NewDefaultOptions() *ConnectionOptions {
return &ConnectionOptions{
Caching: defaultCaching,
Timeout: defaultTimeout,
}
}
// NewConnect creates a connection with options.
func NewConnect(addr string, opts *ConnectionOptions) (*Connection, error) {
return &Connection{
addr: addr,
cache: opts.Caching,
timeout: opts.Timeout,
}, nil
}
使用这种方式,虽然只需要实现一个函数来创建实例,但是也有缺点:为了创建 Connection 实例,每次我们都要创建 ConnectionOptions,操作起来比较麻烦。
那么有没有更优雅的解决方法呢?答案当然是有的,就是使用选项模式来创建实例。以下代码通过选项模式实现上述功能:
package options
import (
"time"
)
type Connection struct {
addr string
cache bool
timeout time.Duration
}
const (
defaultTimeout = 10
defaultCaching = false
)
type options struct {
timeout time.Duration
caching bool
}
// Option overrides behavior of Connect.
type Option interface {
apply(*options)
}
type optionFunc func(*options)
func (f optionFunc) apply(o *options) {
f(o)
}
func WithTimeout(t time.Duration) Option {
return optionFunc(func(o *options) {
o.timeout = t
})
}
func WithCaching(cache bool) Option {
return optionFunc(func(o *options) {
o.caching = cache
})
}
// Connect creates a connection.
func NewConnect(addr string, opts ...Option) (*Connection, error) {
options := options{
timeout: defaultTimeout,
caching: defaultCaching,
}
for _, o := range opts {
o.apply(&options)
}
return &Connection{
addr: addr,
cache: options.caching,
timeout: options.timeout,
}, nil
}
在上面的代码中,首先我们定义了options结构体,它携带了 timeout、caching 两个属性。接下来,我们通过NewConnect创建了一个连接,NewConnect函数中先创建了一个带有默认值的options结构体变量,并通过调用
for _, o := range opts {
o.apply(&options)
}
来修改所创建的options结构体变量。
需要修改的属性,是在NewConnect时,通过 Option 类型的选项参数传递进来的。可以通过WithXXX函数来创建 Option 类型的选项参数:WithTimeout、WithCaching。
Option 类型的选项参数需要实现apply(*options)函数,结合 WithTimeout、WithCaching 函数的返回值和 optionFunc 的 apply 方法实现,可以知道o.apply(&options)其实就是把 WithTimeout、WithCaching 传入的参数赋值给 options 结构体变量,以此动态地设置 options 结构体变量的属性。
这里还有一个好处:我们可以在 apply 函数中自定义赋值逻辑,例如o.timeout = 100 * t。通过这种方式,我们会有更大的灵活性来设置结构体的属性。
选项模式有很多优点,例如:支持传递多个参数,并且在参数发生变化时保持兼容性;支持任意顺序传递参数;支持默认值;方便扩展;通过 WithXXX 的函数命名,可以使参数意义更加明确,等等。
不过,为了实现选项模式,我们增加了很多代码,所以在开发中,要根据实际场景选择是否使用选项模式。选项模式通常适用于以下场景:
- 结构体参数很多,创建结构体时,我们期望创建一个携带默认值的结构体变量,并选择性修改其中一些参数的值。
- 结构体参数经常变动,变动时我们又不想修改创建实例的函数。例如:结构体新增一个 retry 参数,但是又不想在 NewConnect 入参列表中添加retry int这样的参数声明。
如果结构体参数比较少,可以慎重考虑要不要采用选项模式。
总结
设计模式,是业界沉淀下来的针对特定场景的最佳解决方案。在软件领域,GoF 首次系统化提出了 3 大类设计模式:创建型模式、结构型模式、行为型模式。
END 链接
✴️版权声明 © :本书所有内容遵循CC-BY-SA 3.0协议(署名-相同方式共享)©